
In basic terms, Sora is a very large computer program trained to associate text captions with corresponding video content. More technically, Sora is a diffusion model (like many other image-generating AI tools), with a transformer encoding system resembling ChatGPT’s. Using an iterative process of removing visual noise from video clips, developers trained Sora to produce outputs from text prompts. The main difference between Sora and an image generator is that instead of encoding text into still pixels, it translates words into temporal-spatial blocks that, together, compose a complete clip. Google’s Lumiere and many other modelswork in a similar way.
At the heart of Sora is a pre-trained diffusion transformer [4]. Transformer models have proven scalable and effective for many natural language tasks. Similar to powerful large language models (LLMs) such as GPT-4, Sora can parse text and comprehend complex user instructions. To make video generation computationally efficient, Sora employs spacetime latent patches as its building blocks. Specifically, Sora compresses a raw input video into a latent spacetime representation. Then, a sequence of latent spacetime patches is extracted from the compressed video to encapsulate both the visual appearance and motion dynamics over brief intervals. These patches, analogous to word tokens in language models, provide Sora with detailed visual phrases to be used to construct videos. Sora’s text-to-video generation is performed by a diffusion transformer model. Starting with a frame filled with visual noise, the model iteratively denoises the image and introduces specific details according to the provided text prompt. In essence, the 3 generated video emerges through a multi-step refinement process, with each step refining the video to be more aligned with the desired content and quality.
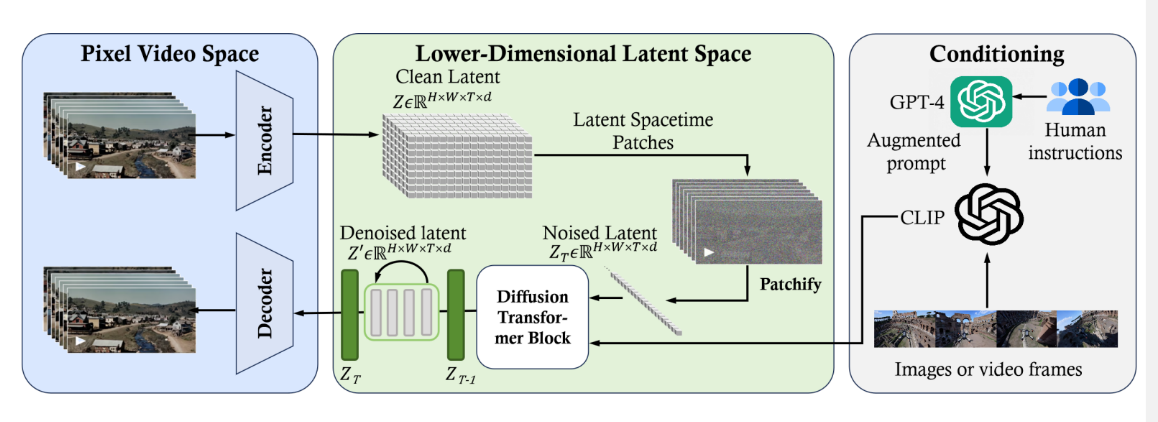
Reverse Engineering: Overview of Sora framework
Sora is a diffusion model, which generates a video by starting off with one that looks like static noise and gradually transforms it by removing the noise over many steps.
Sora is capable of generating entire videos all at once or extending generated videos to make them longer. By giving the model foresight of many frames at a time, we’ve solved a challenging problem of making sure a subject stays the same even when it goes out of view temporarily.
Similar to GPT models, Sora uses a transformer architecture, unlocking superior scaling performance.
We represent videos and images as collections of smaller units of data called patches, each of which is akin to a token in GPT. By unifying how we represent data, we can train diffusion transformers on a wider range of visual data than was possible before, spanning different durations, resolutions and aspect ratios.
Sora builds on past research in DALL·E and GPT models. It uses the recaptioning technique from DALL·E 3, which involves generating highly descriptive captions for the visual training data. As a result, the model is able to follow the user’s text instructions in the generated video more faithfully.
In addition to being able to generate a video solely from text instructions, the model is able to take an existing still image and generate a video from it, animating the image’s contents with accuracy and attention to small detail. The model can also take an existing video and extend it or fill in missing frames.
Sora serves as a foundation for models that can understand and simulate the real world, a capability we believe will be an important milestone for achieving AGI.
Sora is able to generate complex scenes with multiple characters, specific types of motion, and accurate details of the subject and background. The model understands not only what the user has asked for in the prompt, but also how those things exist in the physical world.
The model has a deep understanding of language, enabling it to accurately interpret prompts and generate compelling characters that express vibrant emotions. Sora can also create multiple shots within a single generated video that accurately persist characters and visual style.
The current model has weaknesses. It may struggle with accurately simulating the physics of a complex scene, and may not understand specific instances of cause and effect. For example, a person might take a bite out of a cookie, but afterward, the cookie may not have a bite mark.
The model may also confuse spatial details of a prompt, for example, mixing up left and right, and may struggle with precise descriptions of events that take place over time, like following a specific camera trajectory.
In conclusion, the revolutionary capabilities of Sora OpenAI have ushered in a new era of possibilities, transforming the landscape of artificial intelligence and natural language processing. The power to generate human-like text, understand context, and facilitate dynamic conversations is an incredible leap forward. As we navigate the exciting realms of innovation and technology, it's essential to stay at the forefront of these advancements.
At Kryzetech, we understand the significance of harnessing cutting-edge technologies to propel businesses and individuals into the future. Our commitment to staying ahead in the ever-evolving tech landscape is unwavering. To explore the full potential of Sora OpenAI and other groundbreaking technologies, visit our website at https://kryzetech.com/. Join us on this journey of discovery and transformation as we embrace the limitless possibilities that AI brings to our digital world. Together, let's shape the future with intelligence and innovation.

Founder & CEO




